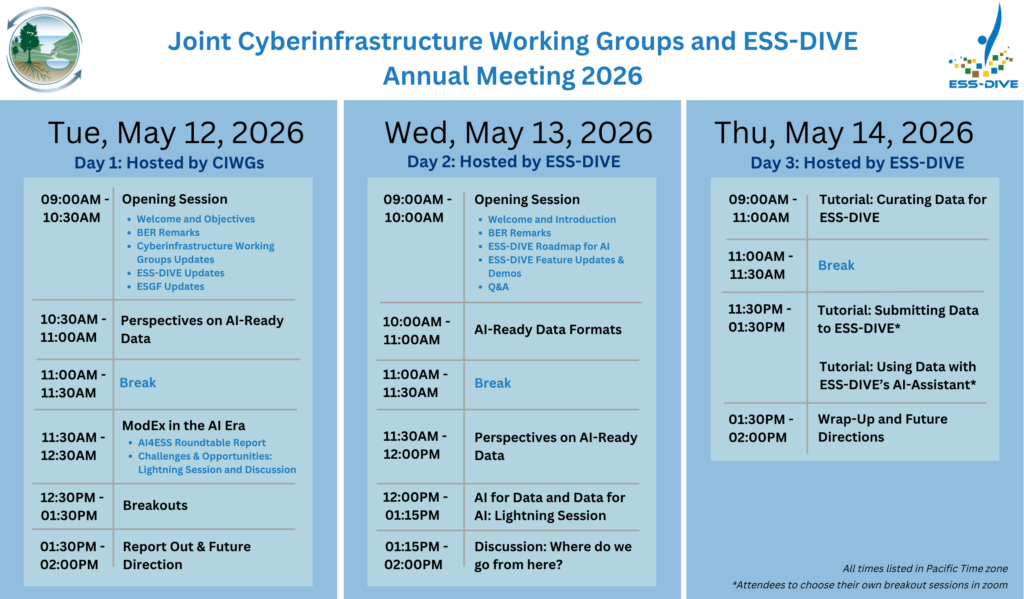
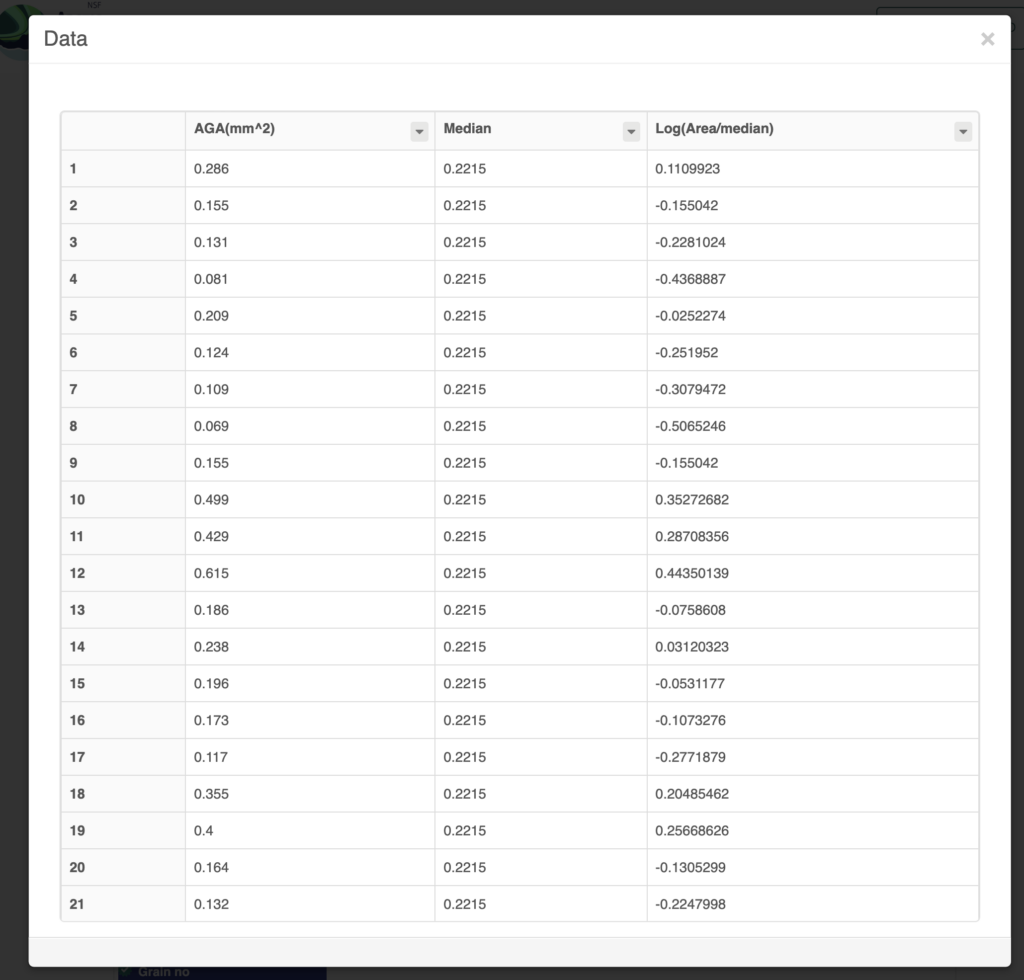
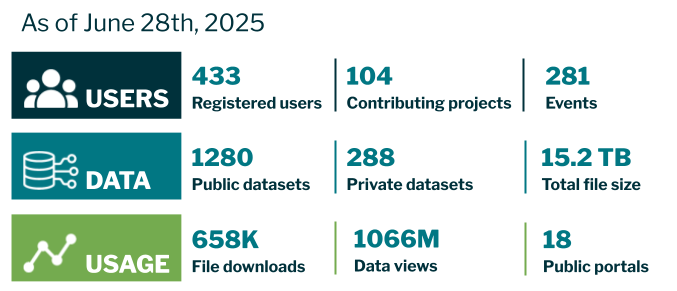
For a detailed agenda of the Day 1 (May 12) meeting, you can visit the Cyberinfrastructure Working Groups events page. For a detailed agenda of Day 2 (May 13) and Day 3 (May 14), you can visit the workshop event page.
On behalf of the United States Department of Energy’s Biological and Environmental Research (BER) program, we cordially invite you to attend the Joint Cyberinfrastructure Working Groups and ESS-DIVE Annual Meeting from May 12th to 14th, 2026. The theme this year will focus on “AI-Ready Data and Models”.
This free and virtual event is a chance for modelers, data contributors and data users to join forces, fostering the exchange of valuable insights and expertise on BER data. Whether you are new to the BER program, CIWGs, ESS-DIVE, or have been engaging for a while, this is your opportunity to learn about the latest updates and AI-approaches within our community, and help drive the future of BER data management, integration, and use.
Here’s what you can expect from this year’s meeting:
- Remarks from BER program managers
- Updates on ESS-DIVE and CIWGs activities;
- Lightning session on AI-perspectives across BER and discussions on future direction for BER data use and preparation;
- Facilitated discussions;
- AI-Ready data curation with Reporting Formats;
- Tutorials on how to curate, publish and use data on ESS-DIVE;
- And more!
Register Now: Registration for the Joint Cyberinfrastructure Working Groups and ESS-DIVE Annual Meeting is now open. While participants are encouraged to attend all three days, they are also welcome to join sessions of their interest. To secure your spot, complete this registration form. Once registered, you will receive a personalized Zoom link, granting you access to the event.