ESS-DIVE Webinar
Monday, February 7 | 11:00-12:00 PT / 14:00-15:00 ET
View Webinar Video / Link to Webinar Slides
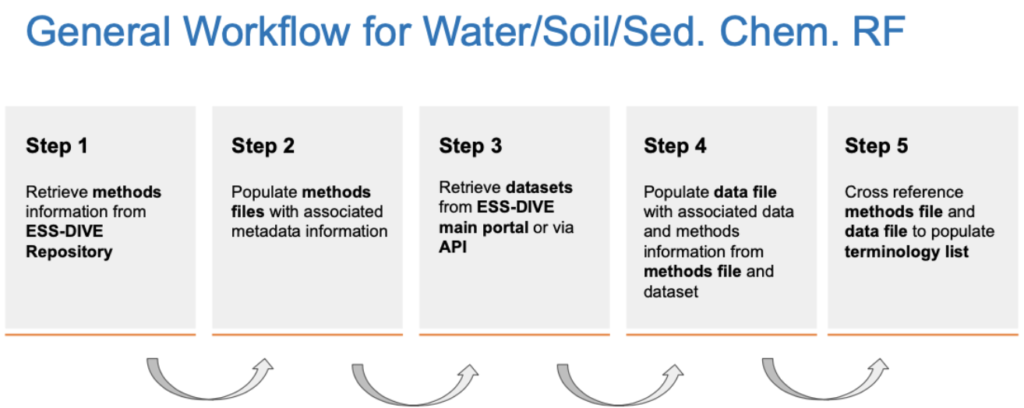
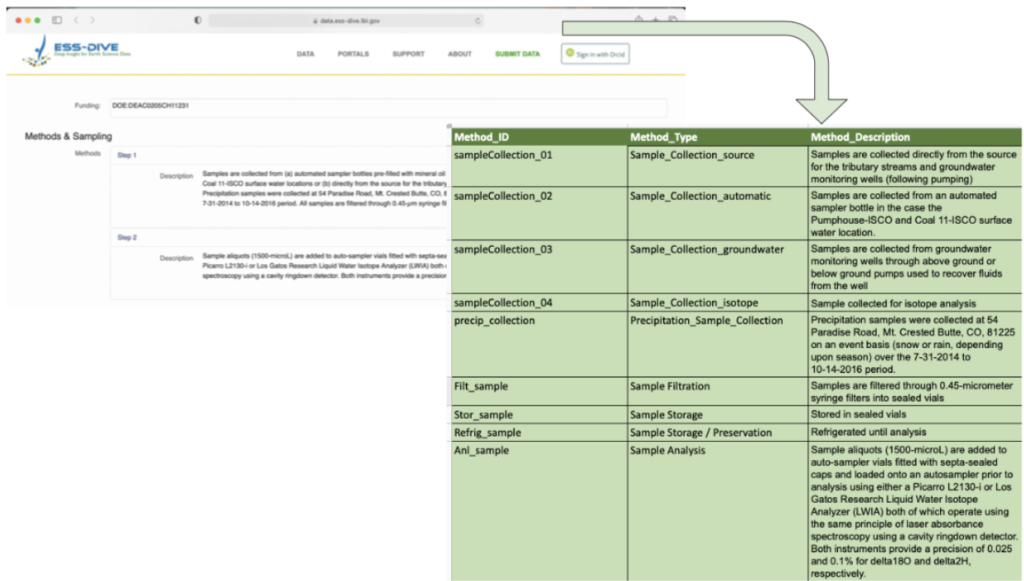
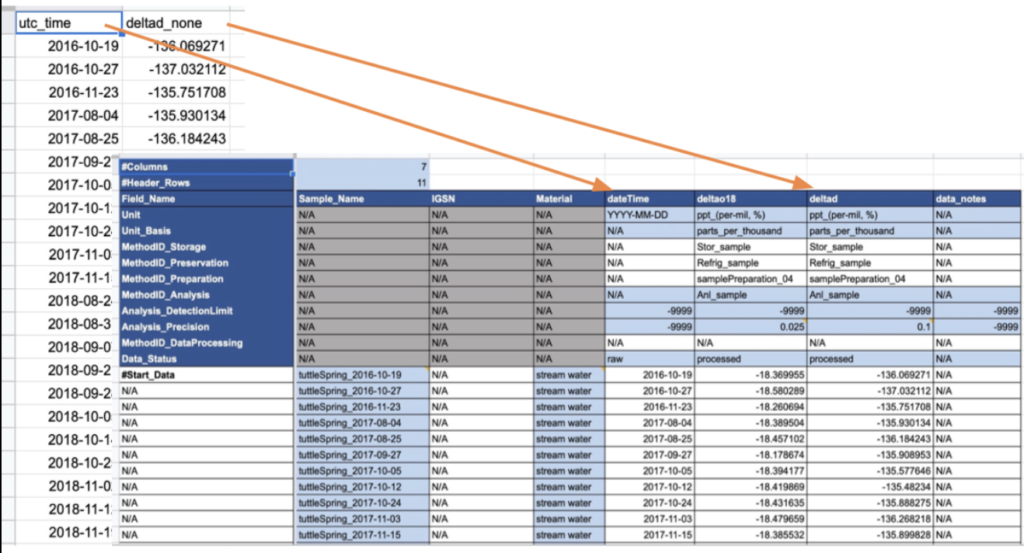
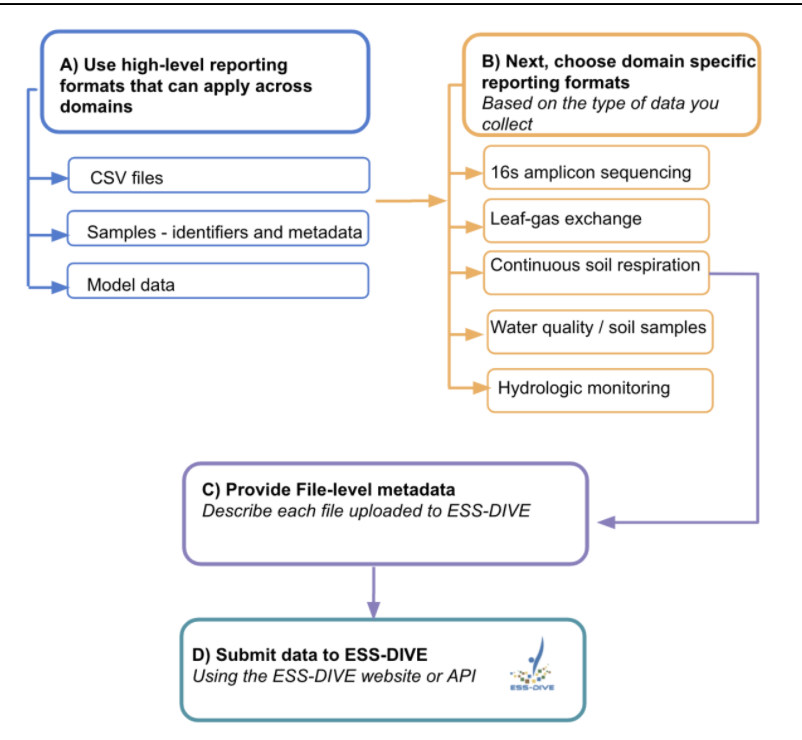
Enhance the discoverability of your datasets by cross-linking relevant data and associated information across repositories. Learn about ESS-DIVE’s new approach and capability to link your ESS-DIVE data to other online repositories and data systems.
This will be a short webinar, with ample time for questions and feedback. We will cover the following use cases for linking your data and metadata:
- Link to individual data files or copies of your data stored elsewhere
- Link to the original publication of a dataset (e.g. your project’s data archive) where metadata and data can be found
- Provide feedback on additional needs for linking to external data, methods, samples, and publications.
Please encourage anyone from your project who may be interested to attend.

Webinar presented by Joan Damerow Lead Scientist
Joan is an environmental scientist with a background in geoscience sampling, freshwater ecology, and biodiversity informatics. She runs activities for ESS-DIVE, including ESS-DIVE webinars, our annual data workshop, and is active in relevant conferences and data working groups (e.g. ESIP, RDA, AGU). Joan is interested in interdisciplinary data management and tracking, and works with DOE ESS data contributors to identify, develop, and implement practical data standards in ESS-DIVE that support FAIR principles.