The Earth Science Information Partners (ESIP) community gathered virtually for the winter 2021 meeting to learn and collaborate around the theme of “Leading Innovation in Earth Science Data Frontiers.” Inspiring plenary talks addressed building a culture of innovation and the exhilarating, but also lonely and frightening, nature of exploring new frontiers in science. There was much discussion around machine learning and AI, and work needed towards assessing and achieving AI-readiness of data across agencies and industries.

Joan Damerow and Rob Crystal-Ornelas from ESS-DIVE attended the meeting, and recap some of the highlights and resources that may be useful for the ESS-DIVE community.
- Joan helped organize a kickoff meeting for the new ESIP Physical Samples Curation Cluster, which will focus initial efforts on identifying high-level recommendations to journal publishers on providing FAIR sample data. We will be meeting on a regular basis to outline core/basic recommendations for sample identifiers and metadata, relevant across disciplines.
- A session on Linking Knowledge in the Earth and Space Sciences discussed how knowledge systems bring together data in a meaningful way to answer useful scientific questions. At ESS-DIVE, we want to know how you would like to search, link, integrate, and reuse data within a larger network. And to ensure that your related data is effectively linked when published.
- Plenary talks on Innovation and New Frontiers in ML/AI introduced real-world examples of how ML/AI can be applied to a range of research priorities, such as monitoring crops and identifying areas of food insecurity in developing countries. Speakers emphasized the continued need for humans in the loop to characterize remote sensing and other data types for ML/AI approaches. Training data is still hard to get, very time-intensive and expensive.
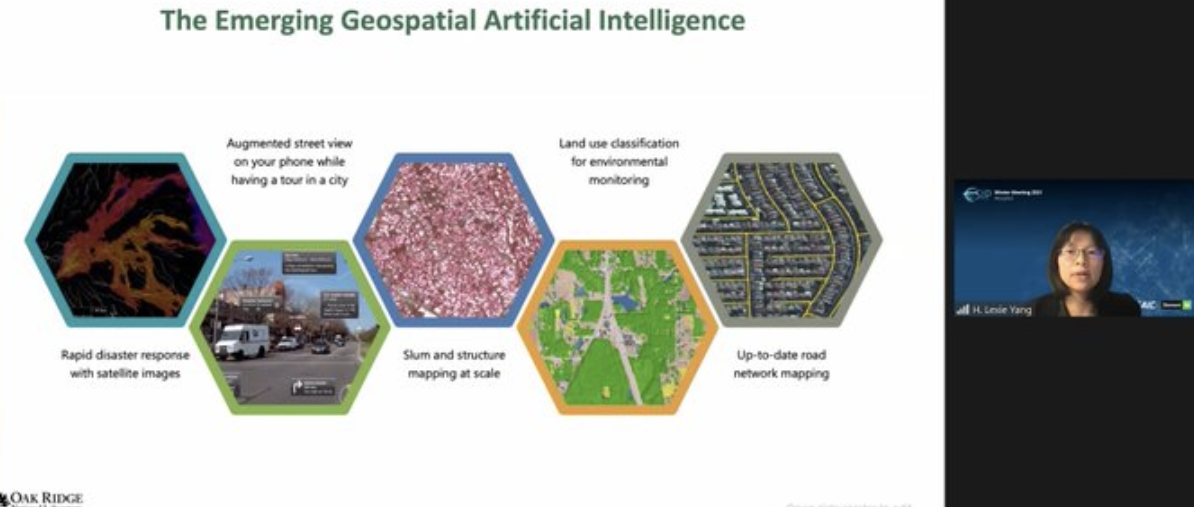
- The Innovating in a Documentation Ecosystem session leveraged the experiences of the audience to identify needs to more effectively link related data within and across agencies and organizations. The ingredients for a connected system involve community engagement, innovative tools and infrastructure, use of metadata standards and conventions, and persistent identifiers. We learned about one particularly useful tool, the metadata editor (mdEditor), and the important role of open APIs. Our next step is to address the challenge of community coordination and work to convince stakeholders to invest in more connected data ecosystems that improve data management efficiency and reusability of data.
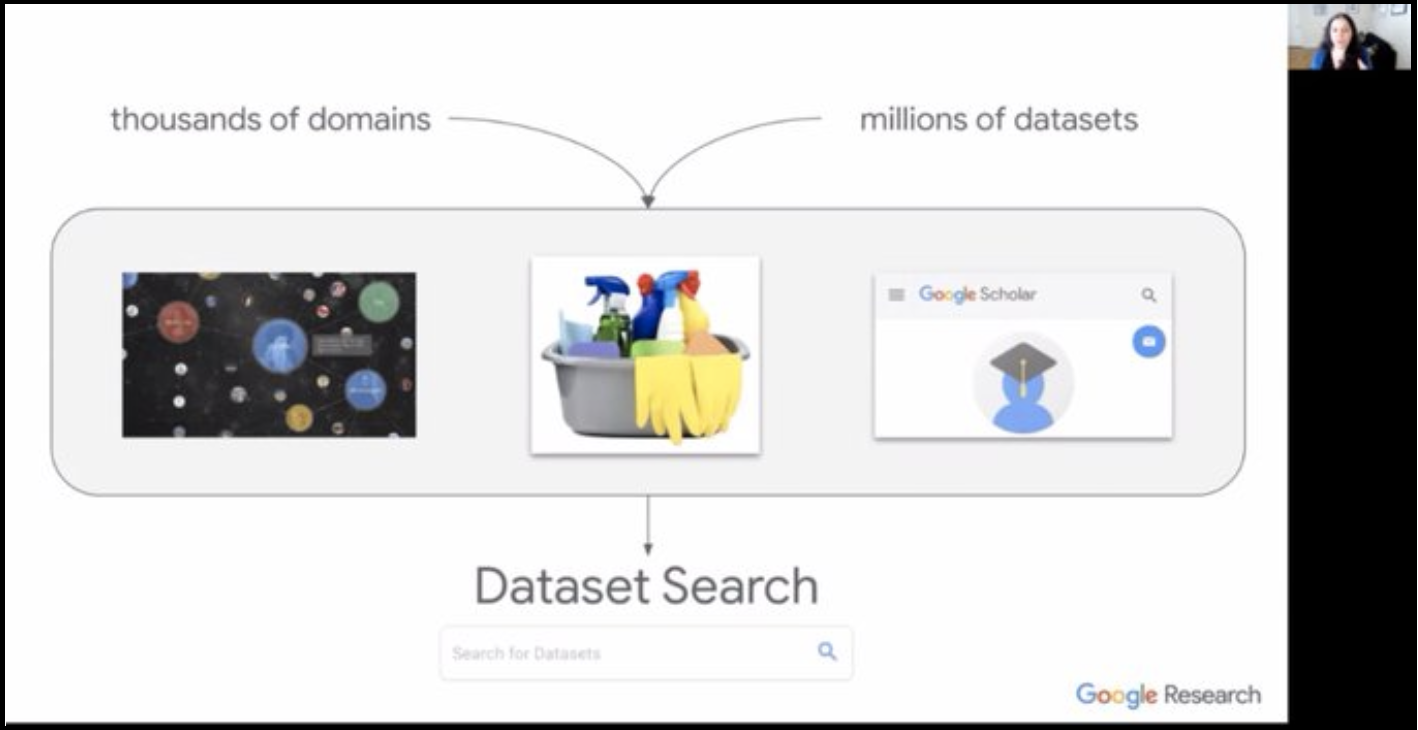
- During plenary talks on Innovation in Open Search and Discovery, we heard from representatives of Schema.org, Google, and Google Dataset Search. The audience promoted the metadata element “variableMeasured” as one of the most important within schema.org for supporting discoverability of datasets. Natasha Noy introduced work exploring the content of Google Dataset Search and how people are searching for data.
- We explored data publication workflows from geoscience researchers to data repositories, and journal publications to identify problem areas. Our next step is to communicate and collaborate with journal publishers towards streamlining the data publication process, and ensure that data is open and useful upon publication.
- A session called “Jupyter Notebooks: Harnessing the full potential” introduced participants to the many ways that the web interface Jupyter can be used for open source code development. We heard about examples of scientists using the Jupyter ecosystem to do everything from create interactive data dashboards, to publishing markdown-style books, to authoring manuscripts for peer reviewed journals.
- In the final organized session of ESIP’s 2021 winter meeting, attendees discussed the challenges and opportunities for defining AI-ready data. The session moderators highlighted the importance of AI-read data for efficiently using novel computing technologies like exascale computing while also recognizing that the definition of AI-ready data is a work in progress. Some of the potential elements of an AI-ready dataset includes: data completeness, documentation (through metadata and data dictionaries), and clear end user licenses.